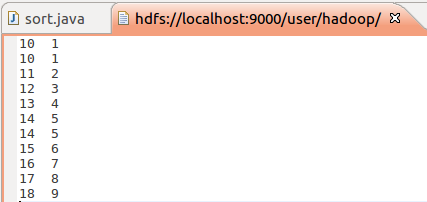
问题描述
将乱序数字按照升序排序。

思路描述
按照mapreduce的默认排序,依次输出key值。
代码
1 package org.apache.hadoop.examples; 2 3 import java.io.IOException; 4 import java.util.Iterator; 5 import java.util.StringTokenizer; 6 import org.apache.hadoop.conf.Configuration; 7 import org.apache.hadoop.fs.Path; 8 import org.apache.hadoop.io.IntWritable; 9 import org.apache.hadoop.io.Text;10 import org.apache.hadoop.mapreduce.Job;11 import org.apache.hadoop.mapreduce.Mapper;12 import org.apache.hadoop.mapreduce.Reducer;13 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;14 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;15 16 public class sort {17 public sort() {18 }19 20 public static void main(String[] args) throws Exception {21 Configuration conf = new Configuration();22 23 String fileAddress = "hdfs://localhost:9000/user/hadoop/";24 25 //String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();26 String[] otherArgs = new String[]{fileAddress+"number.txt", fileAddress+"output"};27 if(otherArgs.length < 2) {28 System.err.println("Usage: sort [ ...] ");29 System.exit(2);30 }31 32 Job job = Job.getInstance(conf, "sort");33 job.setJarByClass(sort.class);34 job.setMapperClass(sort.TokenizerMapper.class);35 //job.setCombinerClass(sort.SortReducer.class);36 job.setReducerClass(sort.SortReducer.class);37 job.setOutputKeyClass(IntWritable.class);38 job.setOutputValueClass(IntWritable.class);39 40 for(int i = 0; i < otherArgs.length - 1; ++i) {41 FileInputFormat.addInputPath(job, new Path(otherArgs[i]));42 }43 44 FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));45 System.exit(job.waitForCompletion(true)?0:1);46 }47 48 49 public static class TokenizerMapper extends Mapper {50 51 public TokenizerMapper() {52 }53 54 public void map(Object key, Text value, Context context) throws IOException, InterruptedException {55 StringTokenizer itr = new StringTokenizer(value.toString());56 57 while(itr.hasMoreTokens()) {58 context.write(new IntWritable(Integer.parseInt(itr.nextToken())), new IntWritable(1));59 }60 61 }62 }63 64 65 public static class SortReducer extends Reducer {66 67 private static IntWritable num = new IntWritable(1);68 69 public SortReducer() {70 }71 72 public void reduce(IntWritable key, Iterable values, Context context) throws IOException, InterruptedException {73 74 for(Iterator i$ = values.iterator(); i$.hasNext();i$.next()) {75 context.write(num, key);76 }77 num = new IntWritable(num.get()+1);78 }79 }80 81 } 
注:不能有combiner操作。
不然就会变成